There are usually 3 CPU cache tiers (L1, L2, L3) nowadays. We use the Principle of locality to determine what data should be stored and removed from this cache.
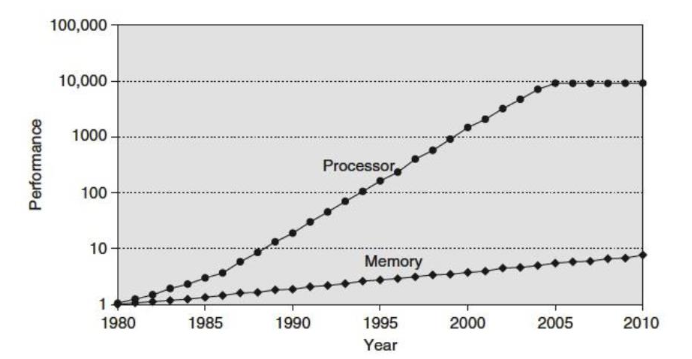
Memory access is the bottleneck. Processor speed has increased much faster than memory access speed (Moore’s Law), so it’s important that relevant data is quick to access to better utilize the CPU. This is the purpose of the cache.
When we wish to access data and it’s not in the cache, this is called a cache miss and we drop down a level in the memory hierarchy (typically, the main memory).
Cache lines
If memory is a big array of data, we can split memory into 64-byte1 “lines” or “blocks” called cache lines. When we access data at a specific address, we bring the whole cache line into the L1 cache.
Spatial locality is applied here.
Replacement policy
When we access data not in the cache and it’s full, then we must evict an existing entry. But how? We first determine which entry in the cache to evict. This is done by calculating the entry slot from the data address itself.
- Least recently used (LRU): if a cache line is used recently, it’s likely to be used again in the near future (temporal locality). So remove the one that hasn’t been accessed the longest.
- Most typically used in caches.
Instruction cache
Since instructions are also bits and are also stored in memory, it is useful to also cache instructions themselves. Therefore we might see stuff like a L1I cache for instructions and L1D cache for data.2
Here, temporal locality matters a bit more; the hardware really likes doing the same set of instructions over and over, and completely finishing the job to move on to a different job.